
Trace and monitor AI agents in production to detect anomalies, debug issues, and drive continuous improvement. OpenTelemetry-native. Model and framework agnostic.
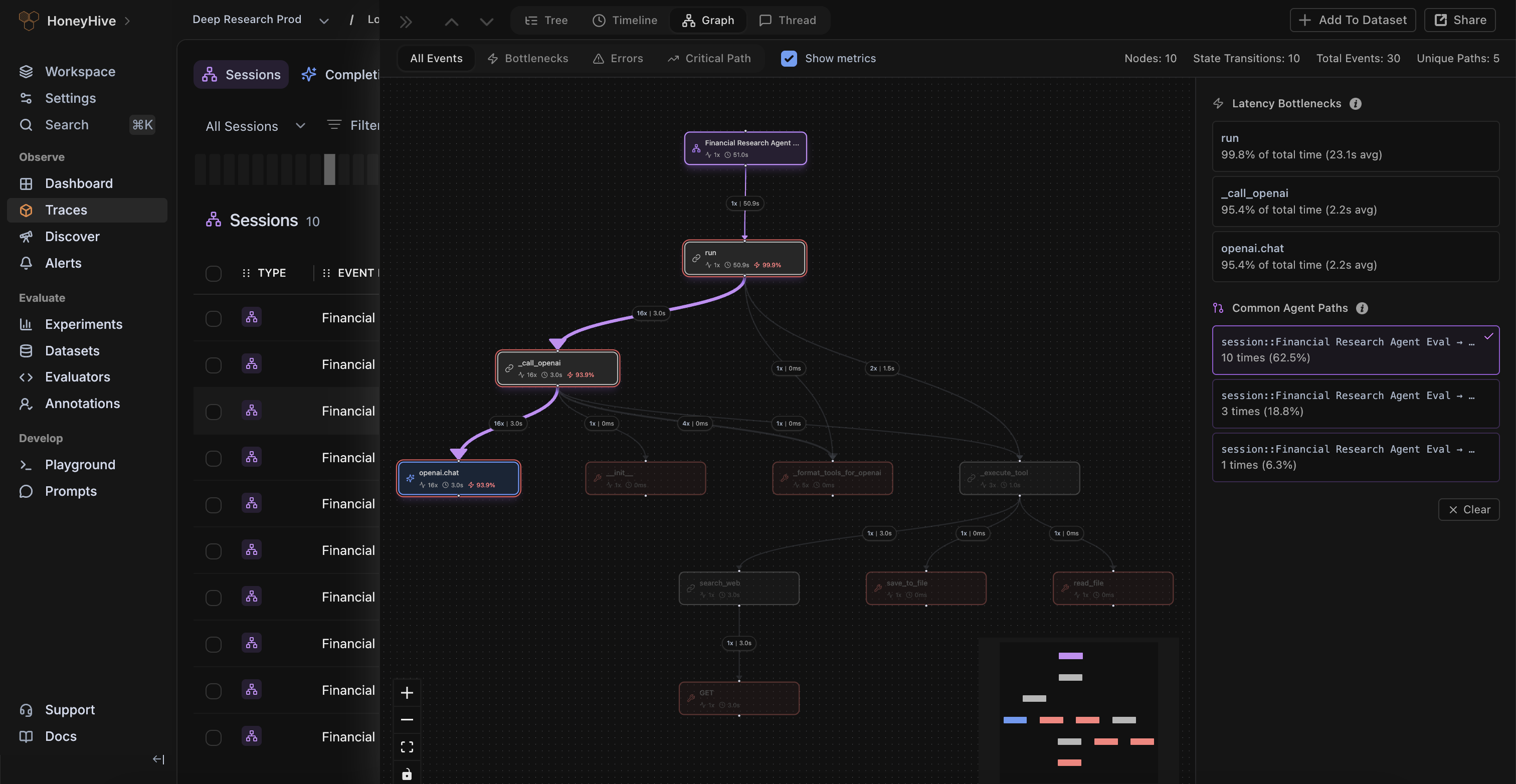
Compute safety, quality, and performance metrics across your data to detect agent failures in production.
Capture user feedback to track performance and user experience across your AI applications.
Visualize complex agentic workflows as DAGs to understand and debug critical error cascades.
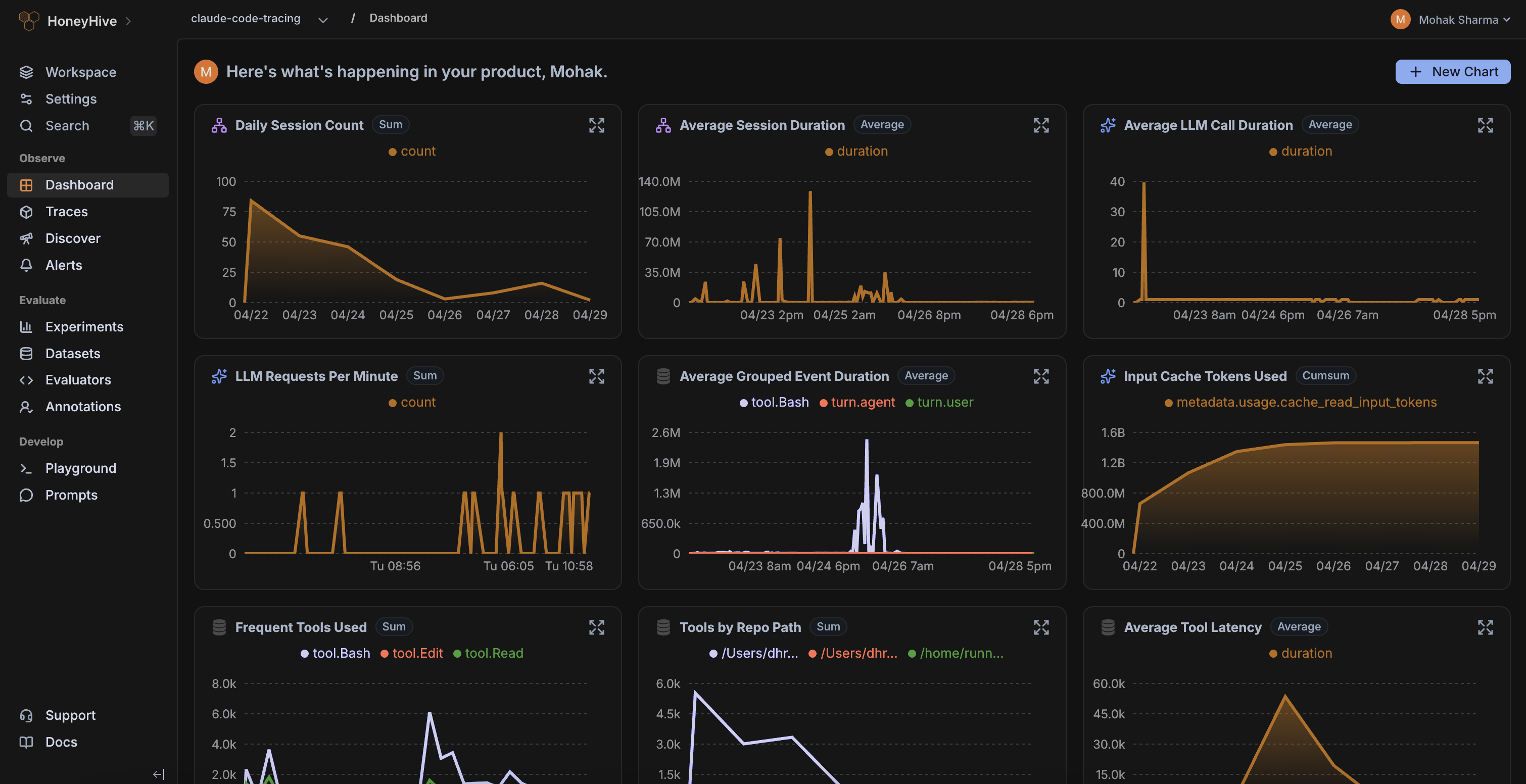
Save custom charts to your team workspace for quick access to insights that matter to you the most.
Slice and dice your data across segments and get detailed insights into application performance.
Log application data synchronously and asynchronously, using our OpenTelemetry-native SDK.
Agents are non-deterministic and lead to unexpected failures in production. HoneyHive allows you to monitor agents with quantitative rigor and get actionable insights to continuously improve your app.
.png)
Trace AI agents with just a few lines of code

Continuously evaluate live traces and capture user feedback.

Create custom queries and monitor key metrics at scale
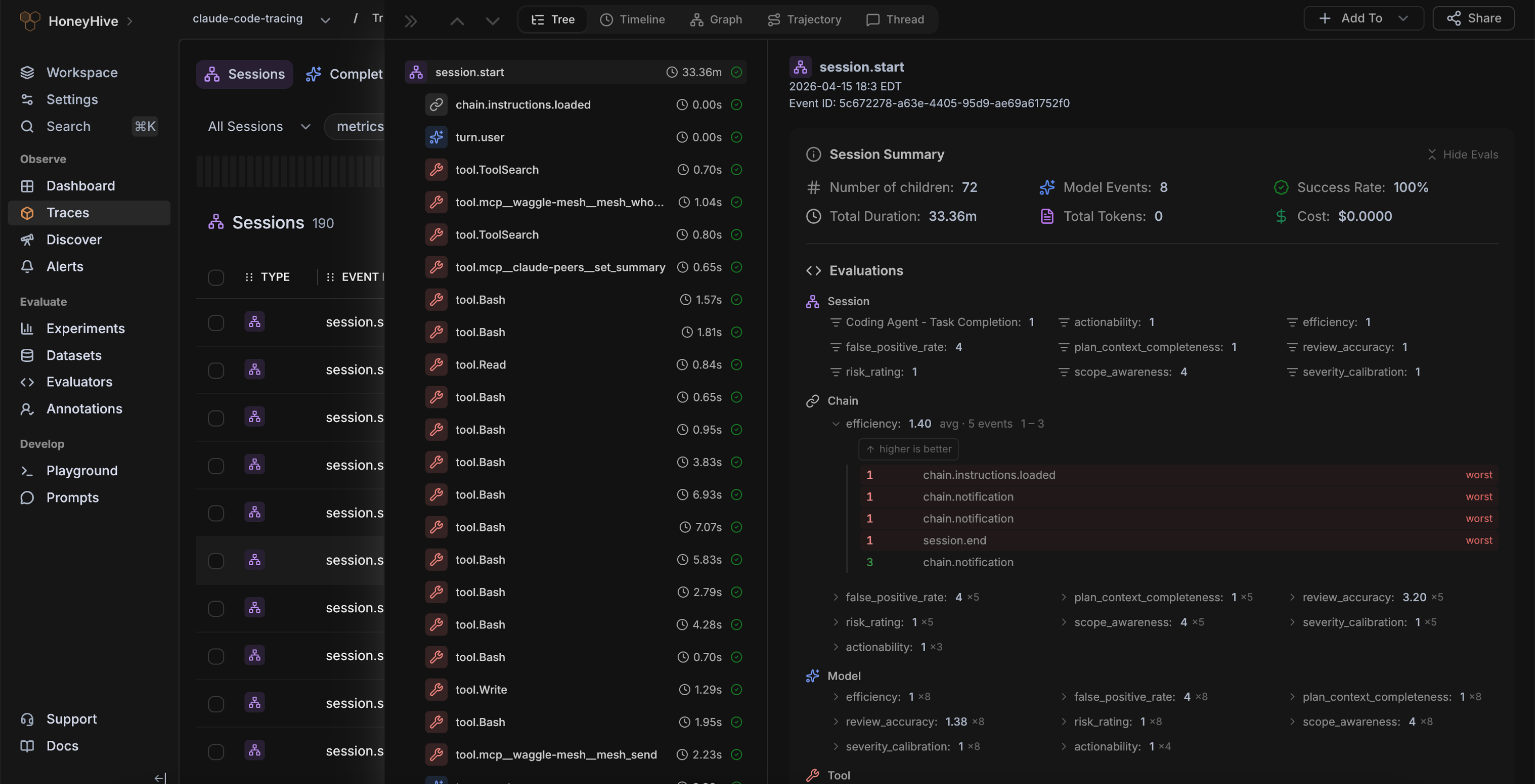
Agents fail due to issues in either the prompt, model, or your data retrieval pipeline. With full visibility into the entire chain of events, you can quickly pinpoint errors and iterate with confidence.

Debug chains, agents, tools and RAG pipelines
.png)
Root cause errors with AI-assisted RCA
Integrates with leading orchestration frameworks
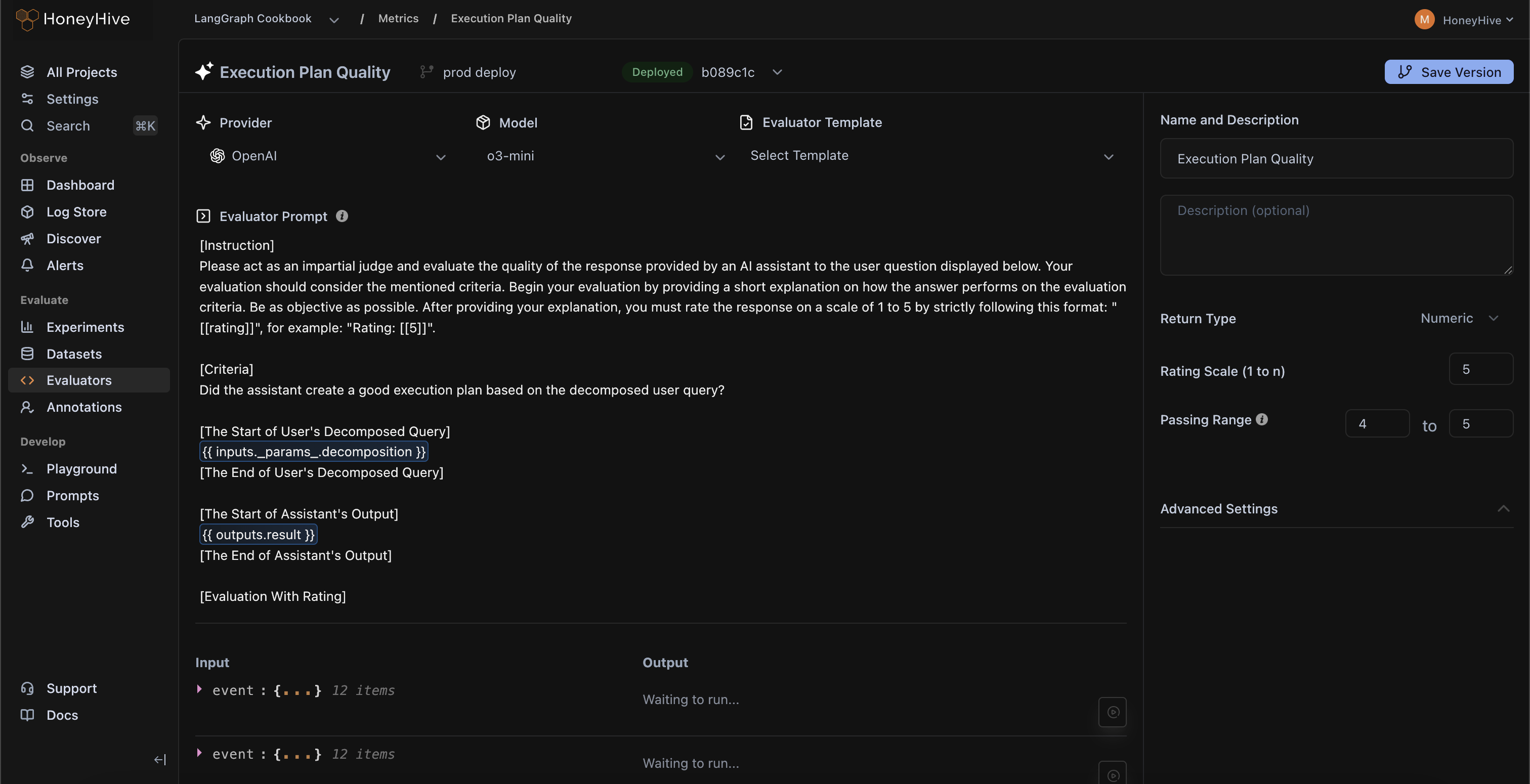
Run online evaluators on your live production data to catch LLM failures automatically.
.png)
Evaluate faithfulness and context relevance across RAG pipelines
Write assertions to validate JSON structures or SQL schemas
Implement moderation filters to detect PII leakage and unsafe responses
Catch agentic failures like tool misuse or looping
Calculate NLP metrics such as ROUGE-L or Edit Distance
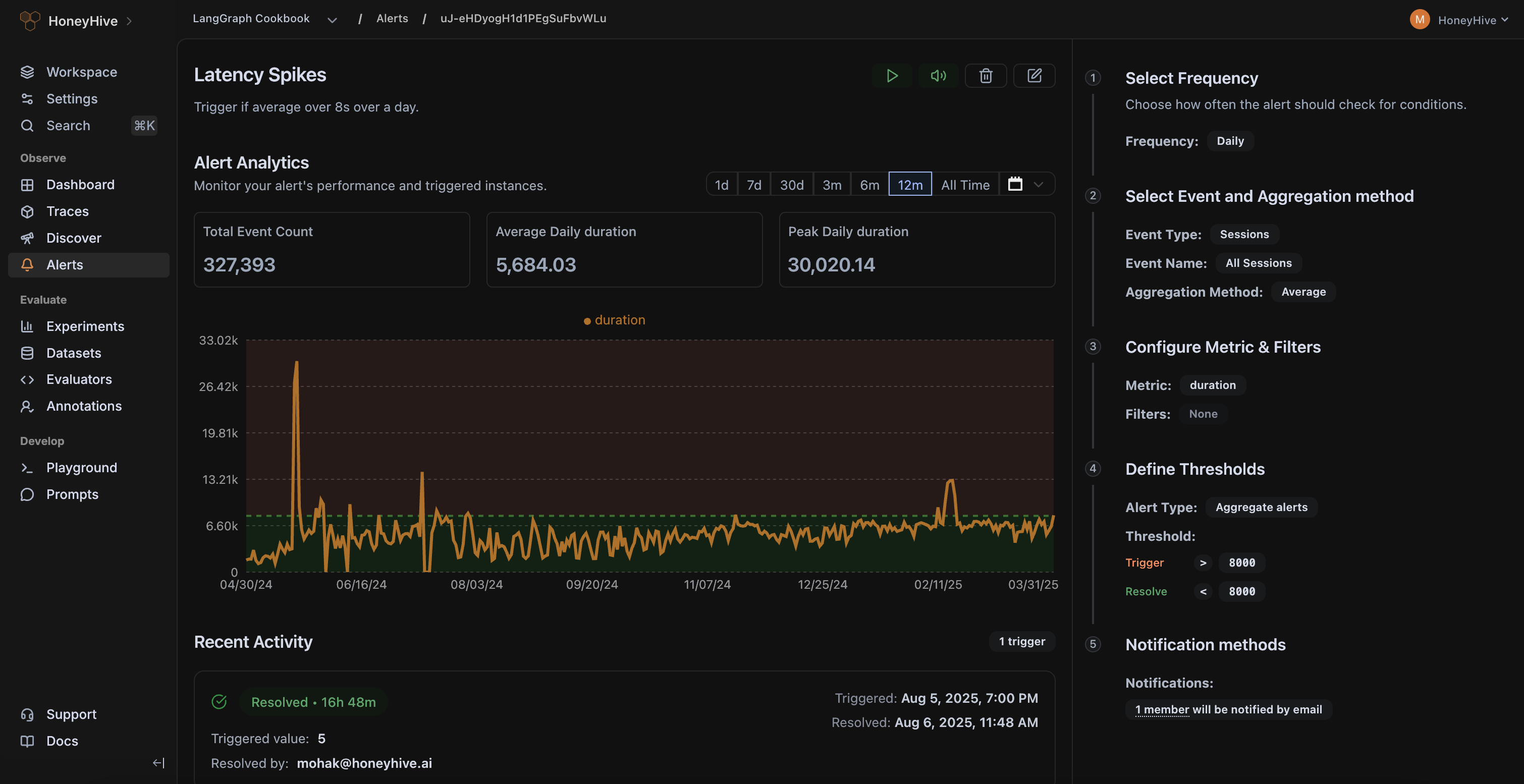
HoneyHive enables you to set up targeted alerts on any schema property to track critical incidents, and run automations to triage and root-cause issues.

Get alerts on cost, latency, accuracy, or guardrail violations
Escalate failing traces to domain experts for human review
Curate datasets from failing traces for future evaluations and resolutions
OpenTelemetry native. Our tracers use OTLP protocol, allowing seamless interoperability across your DevOps stack.
.png)
SDKs and APIs. Allow you to deeply integrate with your application logic and build custom automations using your logs.
.png)
Auto-instrumentation. Our tracers automatically instrument popular model providers and tools like OpenAI, Anthropic, Pinecone, and more.
.png)
HoneyHive powers observability and evaluation across mission-critical AI systems at CBA, enabling safe and responsible deployment of AI agents serving 17M+ consumers.
.jpg)