HoneyHive unifies observability and evaluation into a continuous improvement loop, so every team can ship quality agents with confidence.
.png)



%20(1).png)

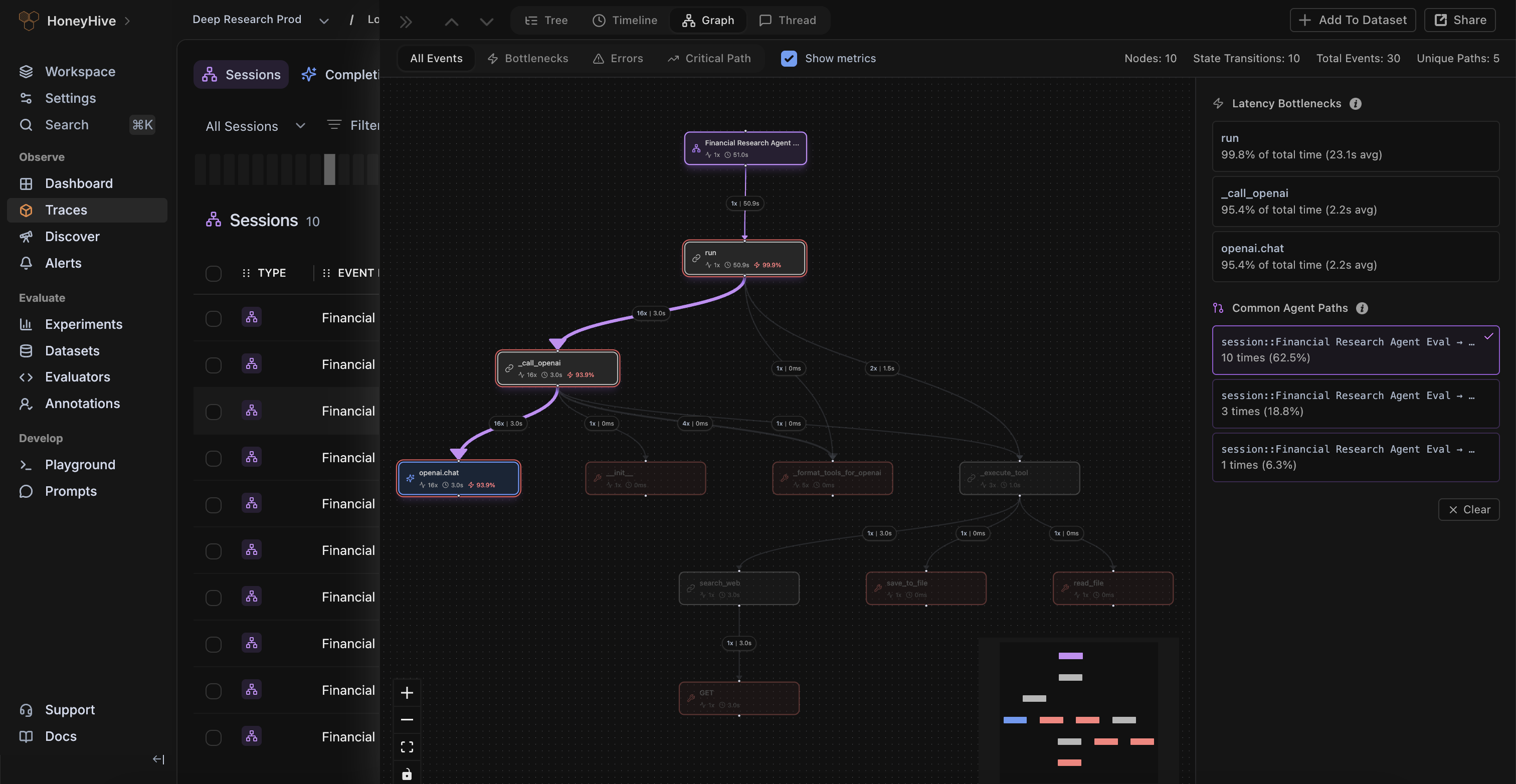
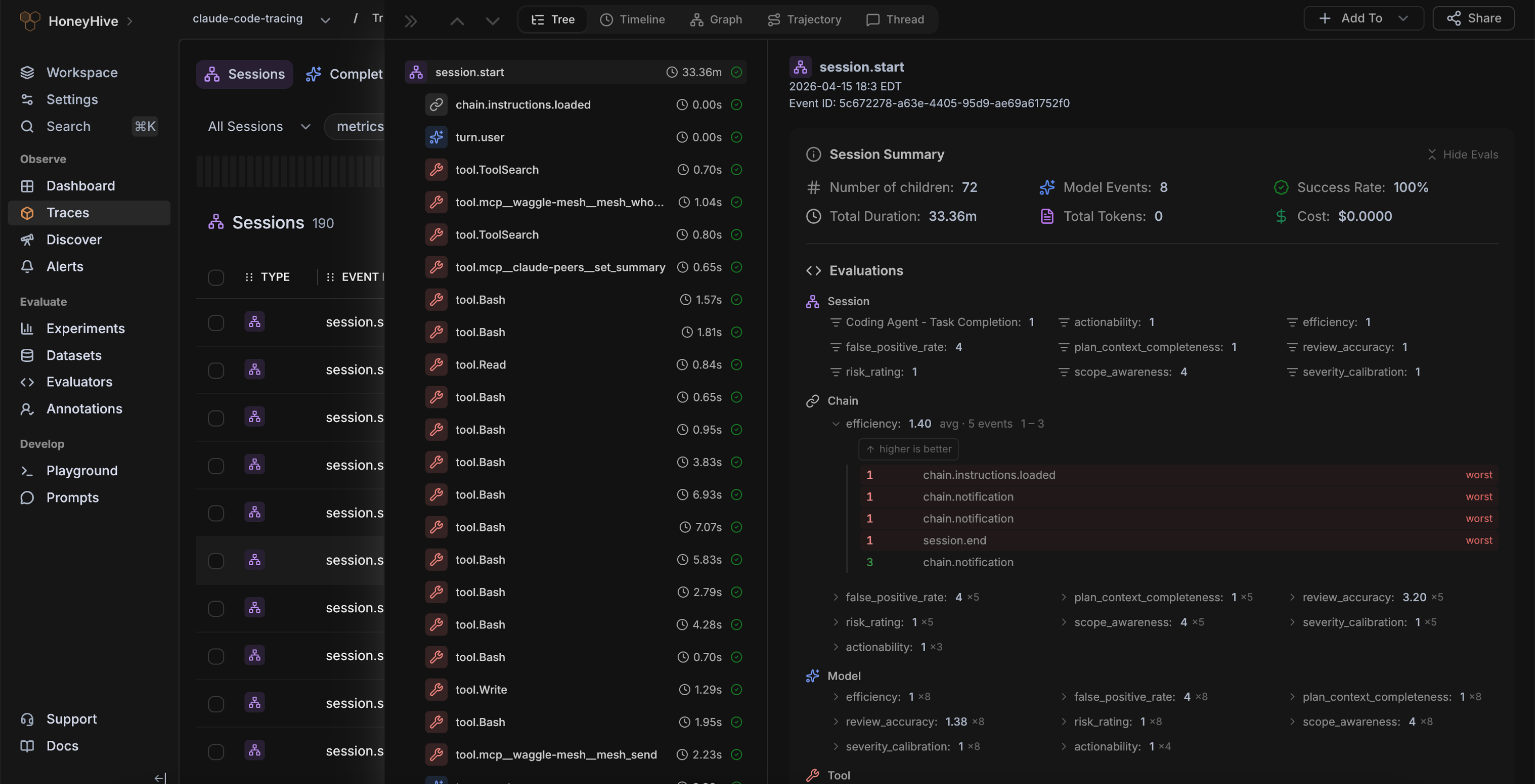
Instrument any agent on any stack with OpenTelemetry — and give every team one shared source of truth to debug agent behavior.


.png)
.png)
.png)
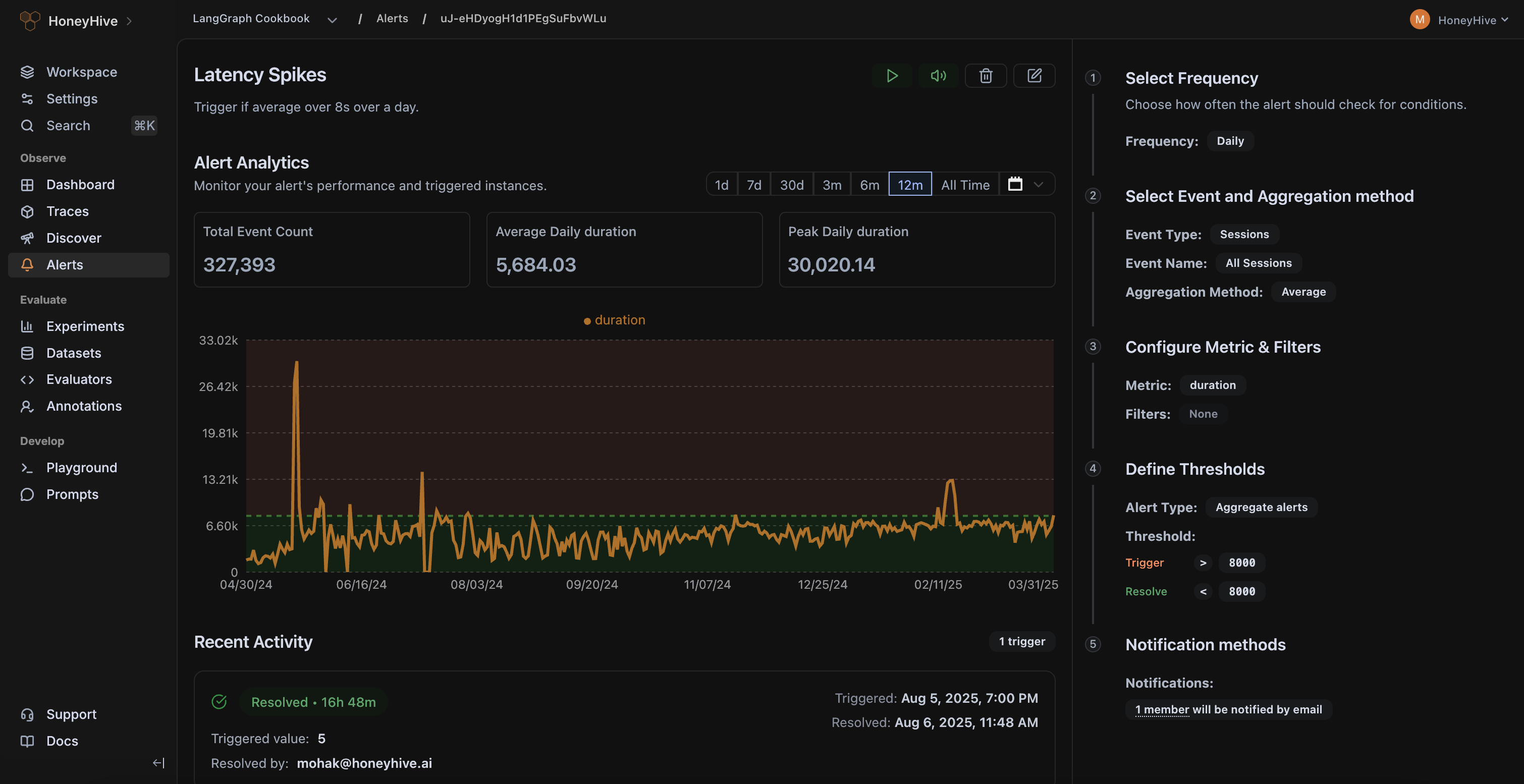
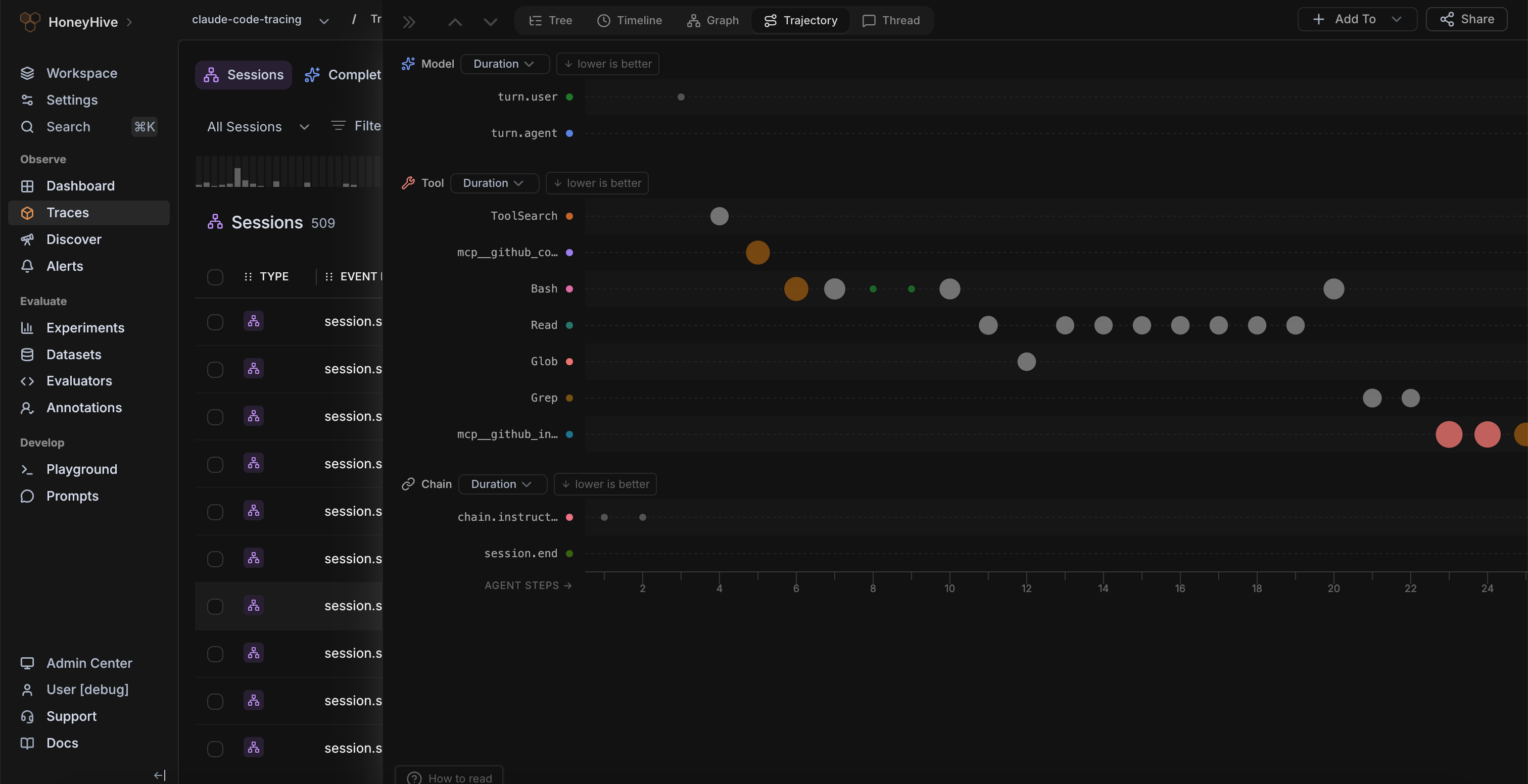
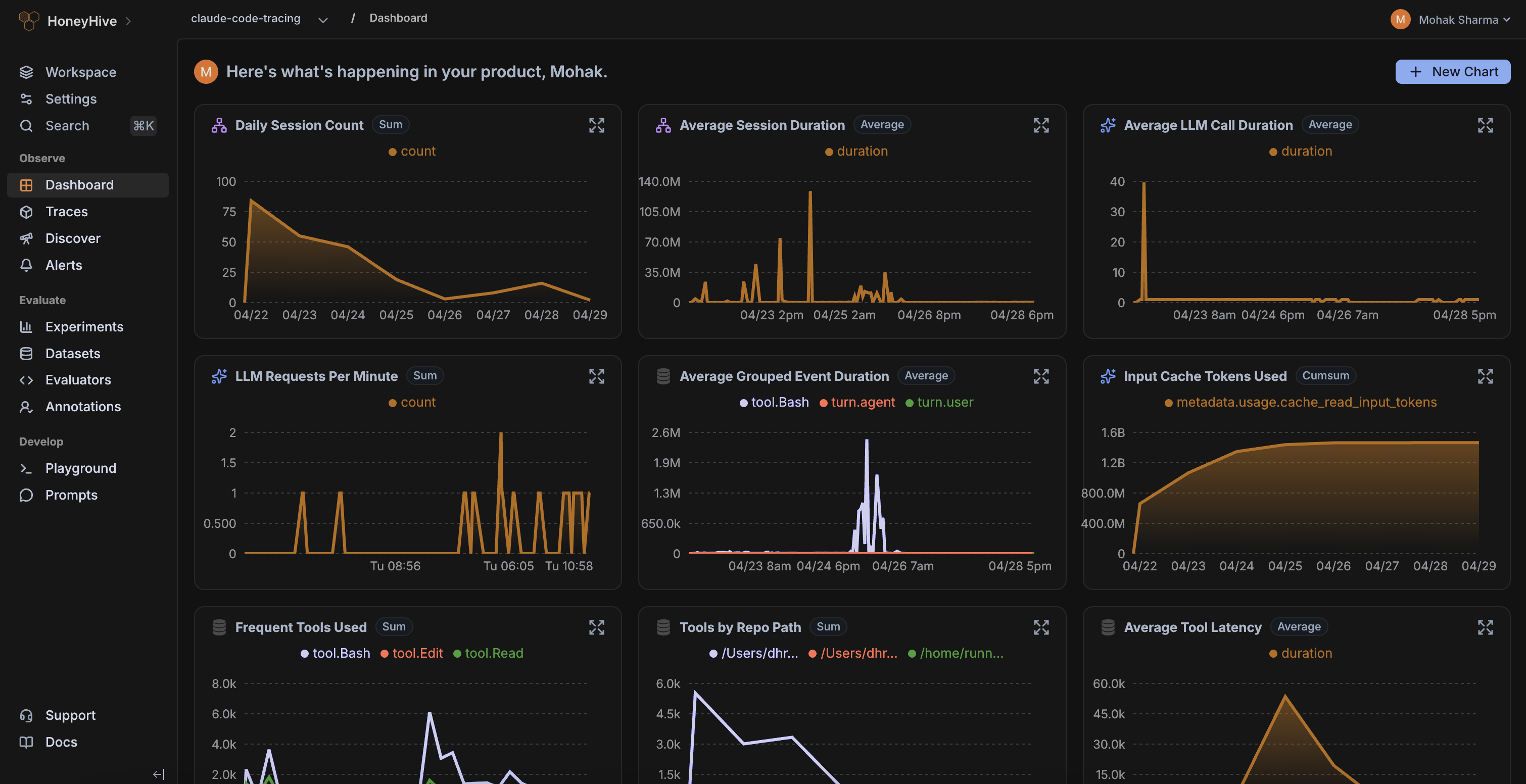
Continuously evaluate live traces, monitor real-world feedback from users, and alert on failures modes that matter to your business.



.png)

.png)
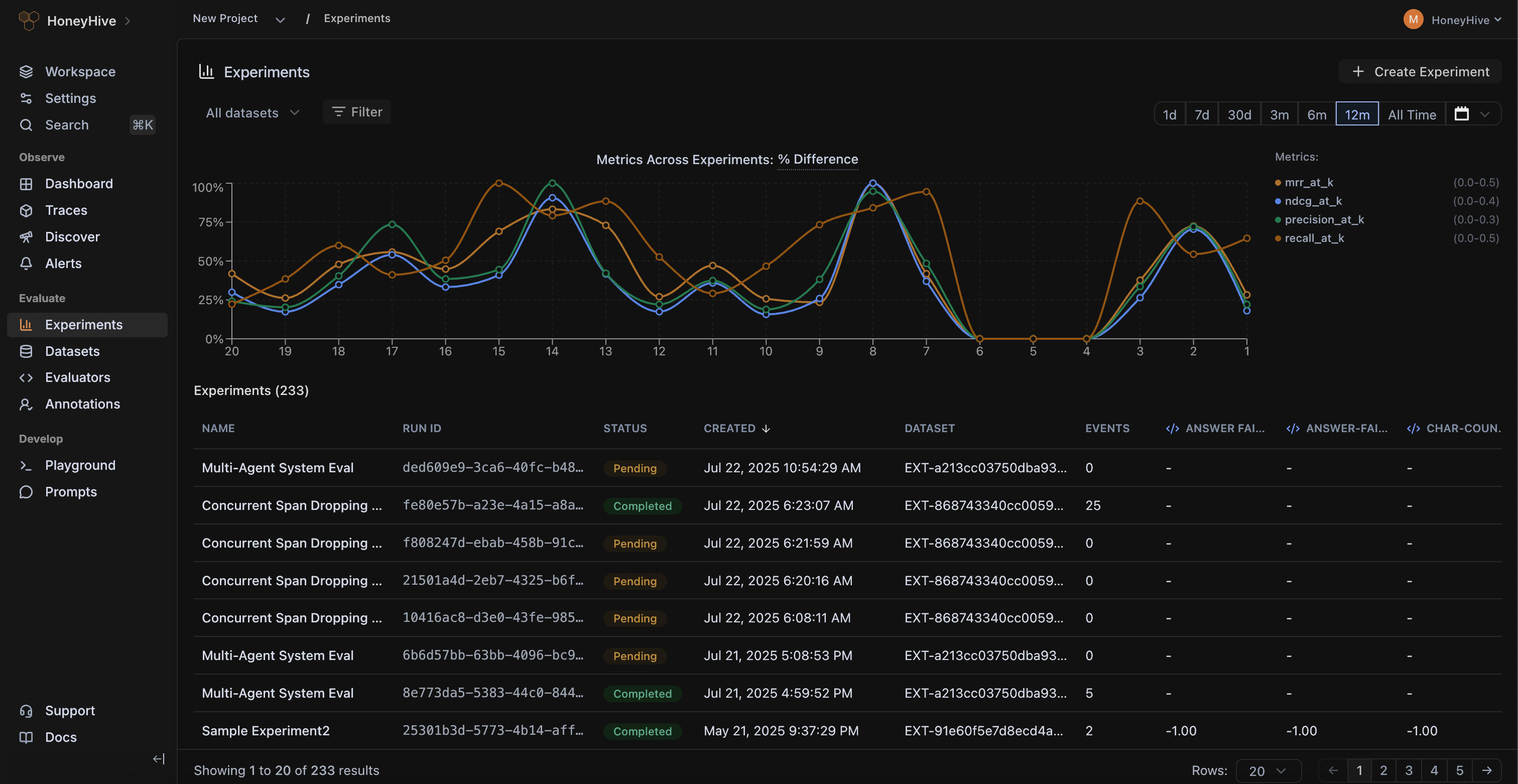
Turn production failures into test suites, compare new changes with baseline, and catch regressions before every release.
.png)
.png)


Bring domain experts into the loop to review edge cases, define quality, and align your evals with real-world business context.


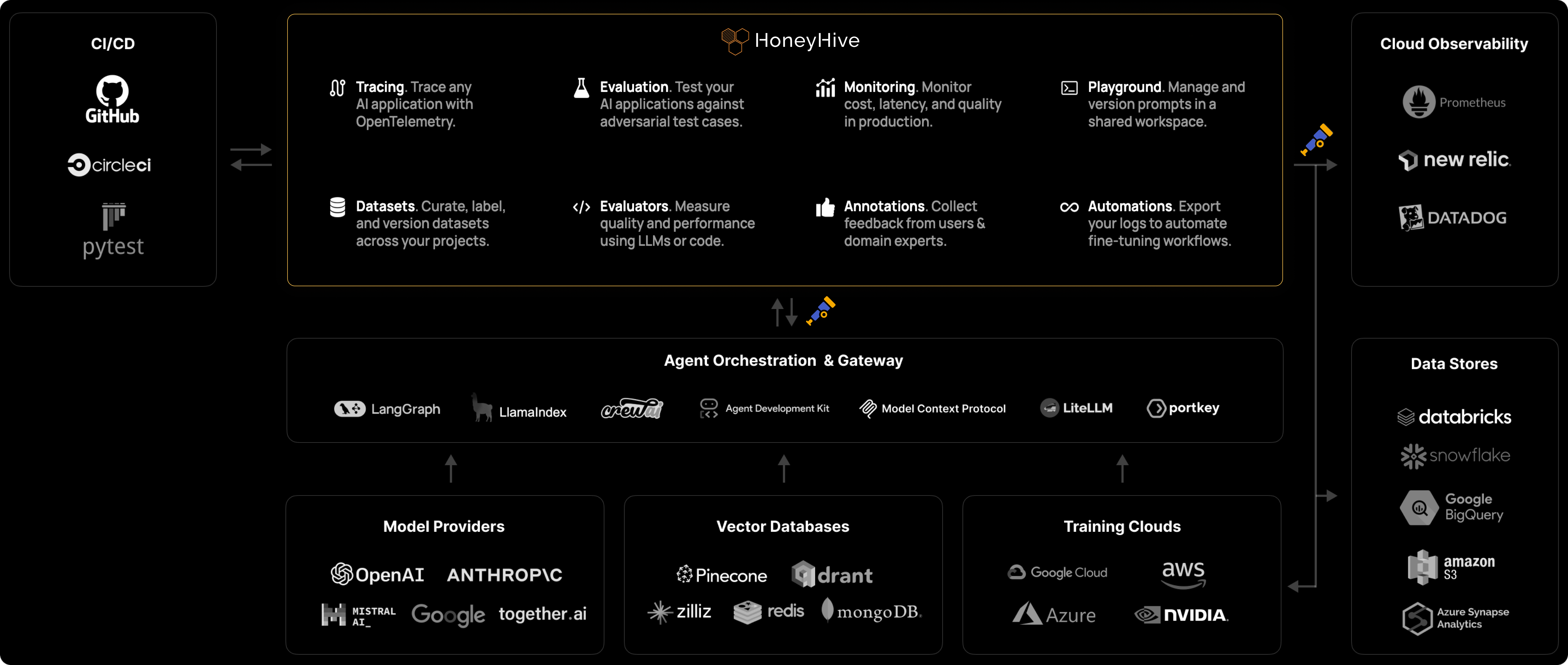
OpenTelemetry-native and framework-agnostic. Integrate with any model, framework, or agent runtime supporting OTel instrumentation.
HoneyHive powers observability and evaluation across dozens of mission-critical AI systems at CBA, enabling safe and responsible deployment of AI agents serving 17M+ consumers.
.jpg)
Agent traces carry rich, highly sensitive I/O that traditional observability can’t handle. HoneyHive is designed specifically for AI traces and keeps your data isolated — logically by default, physically when you need to.
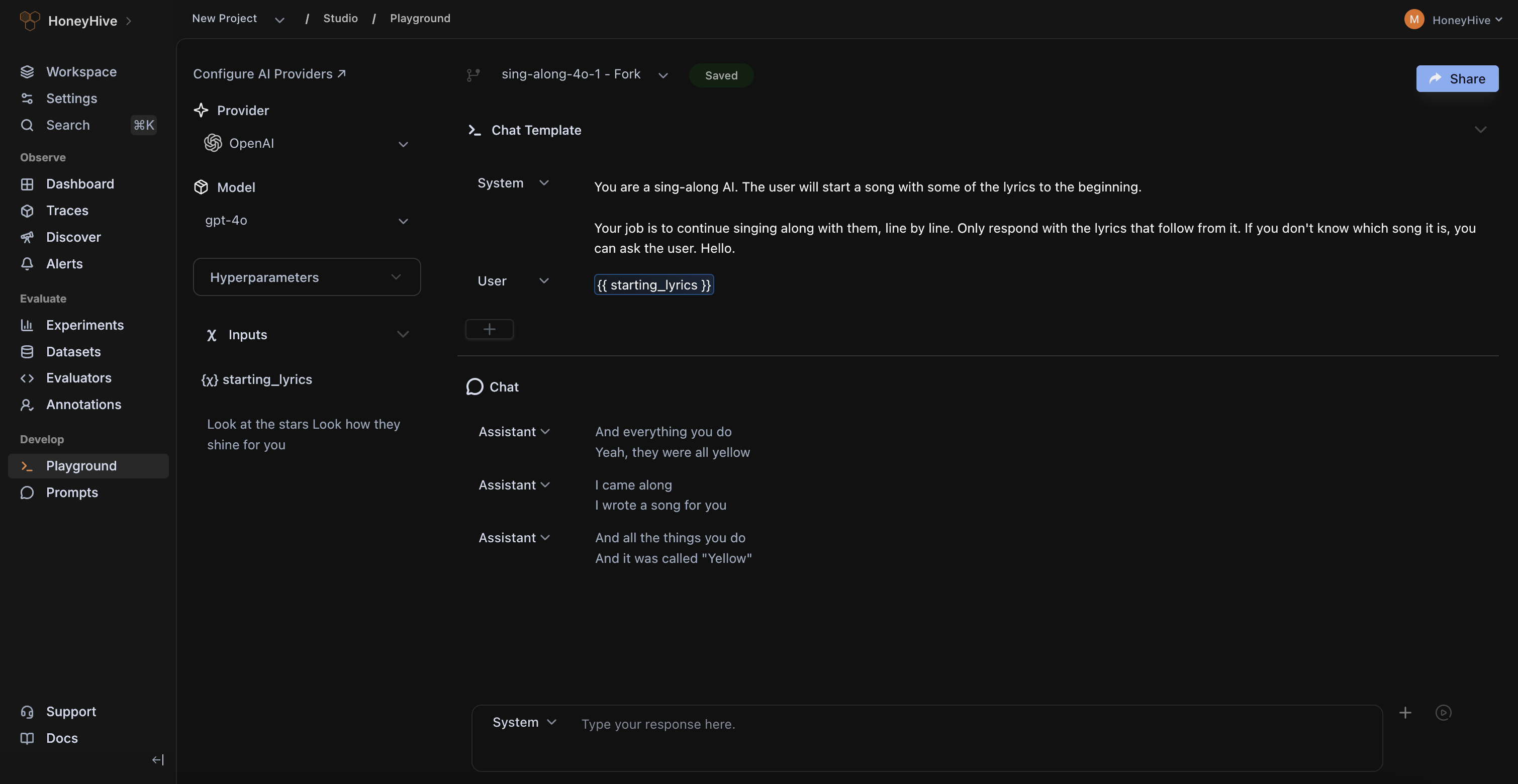
Ready-made skills, a full-feature CLI, and a docs MCP server mean your coding agents can set up tracing, write evals, and drive improvements autonomously for you.