
One platform for every team in your organization to observe, evaluate, and govern AI agents in production.
.png)


%20(1).png)
%20(1).png)

.png)
Trace end-to-end AI workflows so teams can debug failures, understand execution paths, and standardize telemetry across every application.


.png)
.png)
.png)
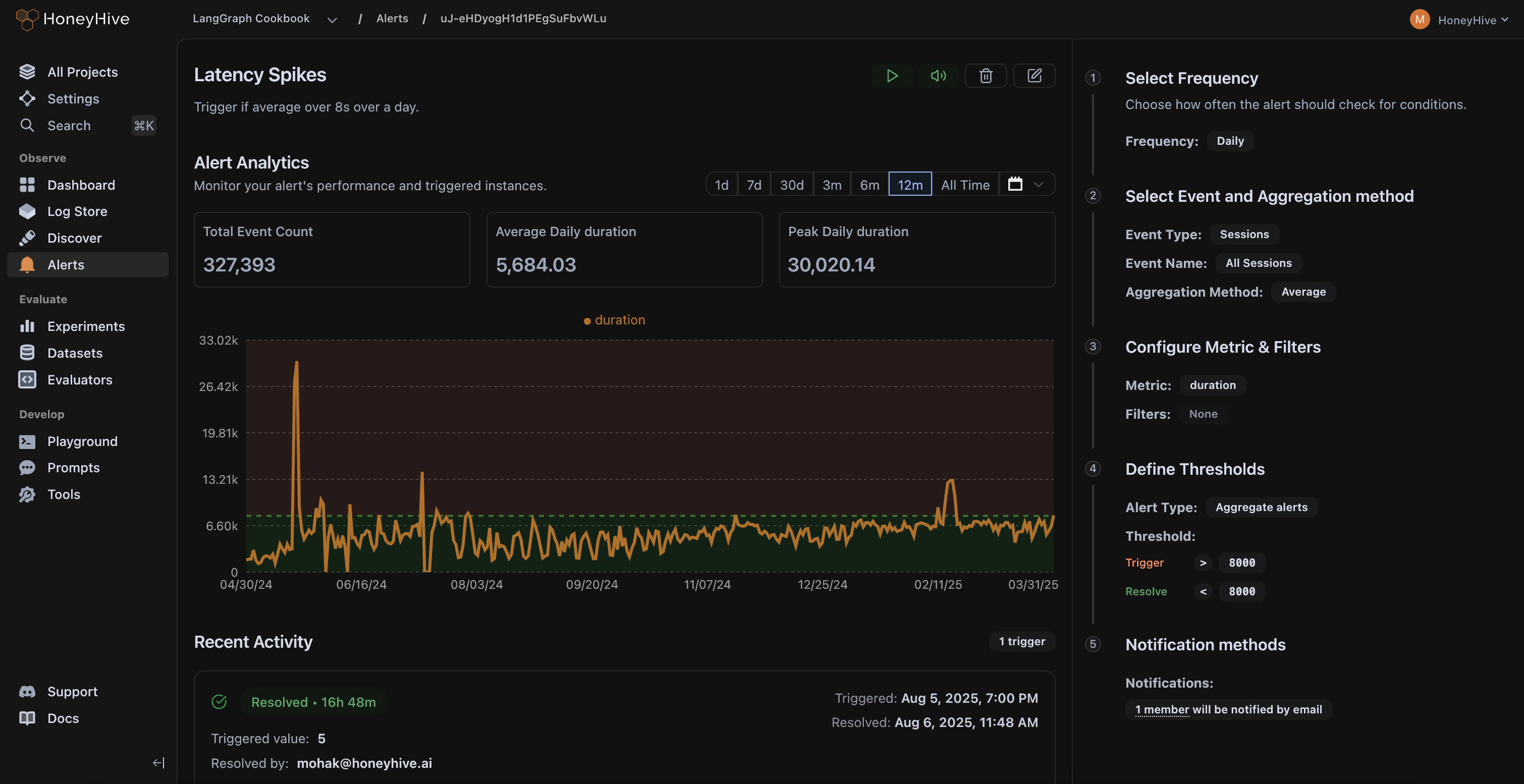
Run online evals on live traffic, track quality alongside latency and cost, and alert on the failure modes that matter to your business.



.png)


Turn production traces into test cases, compare agents and workflows side-by-side, and catch regressions before every release.
.png)
.png)


Bring subject matter experts into the loop to review edge cases, define quality, and align your evals with real-world business context.


.png)
.png)
.png)
SOC 2 Type II certified. GDPR and HIPAA compliant. SSO, SAML, RBAC, and self-hosting available.
Trust Center ↗


SOC-2 Type II, GDPR, and HIPAA compliant to meet your security needs.


Choose between multi-tenant SaaS, single-tenant SaaS, hybrid SaaS, or full self-hosting.

Project & workspace isolation, SAML/SSO, custom permission groups.
HoneyHive powers observability, evaluation, and governance across mission-critical AI systems at CBA, enabling safe and responsible use of AI agents serving 17M+ consumers.
.jpg)
.png)
.png)
.png)