
Your single platform to observe, evaluate, and optimize AI agents — whether you're just getting started or scaling AI across the enterprise.
.png)


%20(1).png)
%20(1).png)

.png)
Instrument end-to-end AI applications—prompts, retrieval, tool calls, MCP servers, and model outputs—so teams can fix issues fast.


.png)
.png)
.png)
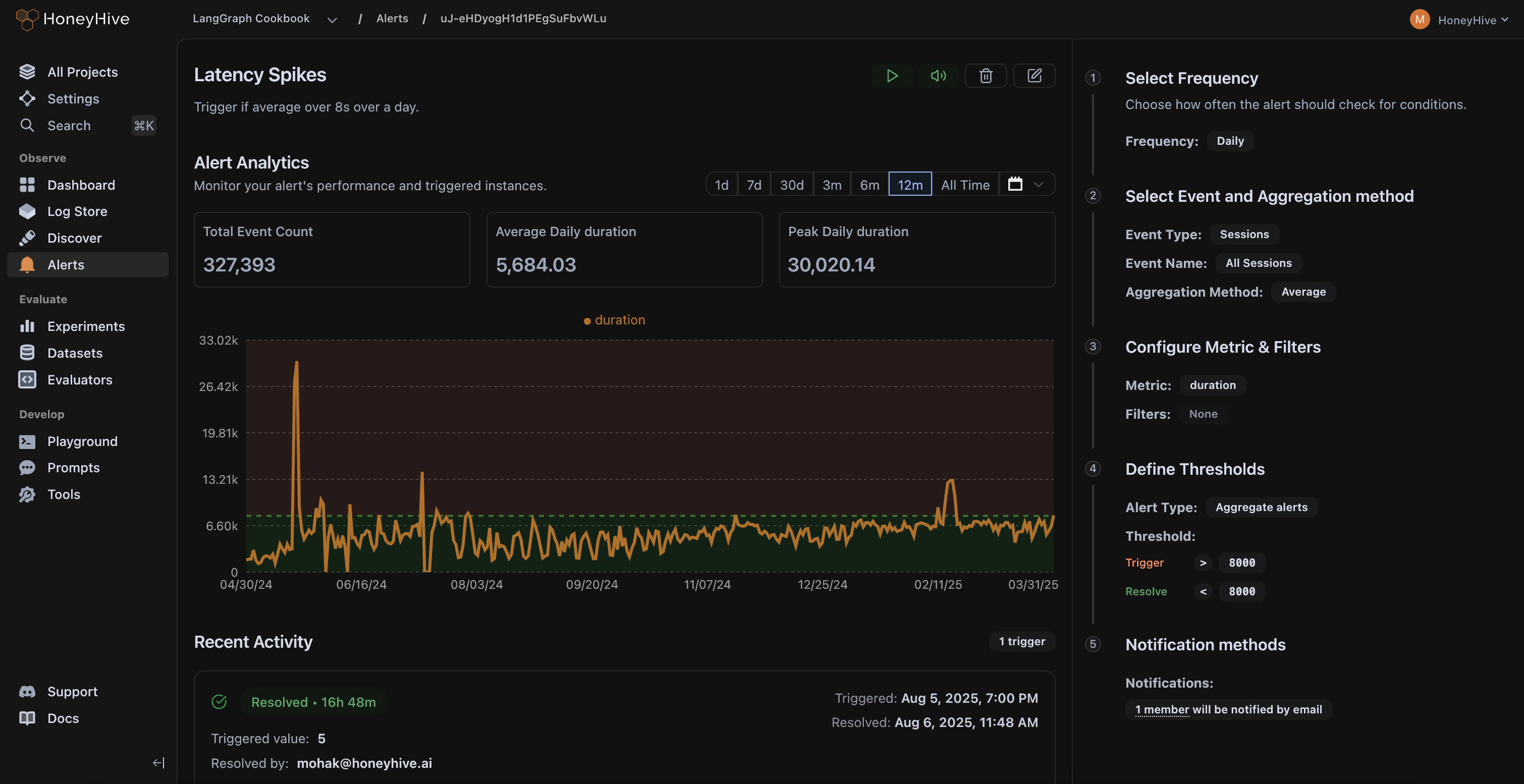
Continuously evaluate live traffic with 25+ pre-built evaluators, get alerts on failures, and automatically escalate issues for human review.



.png)


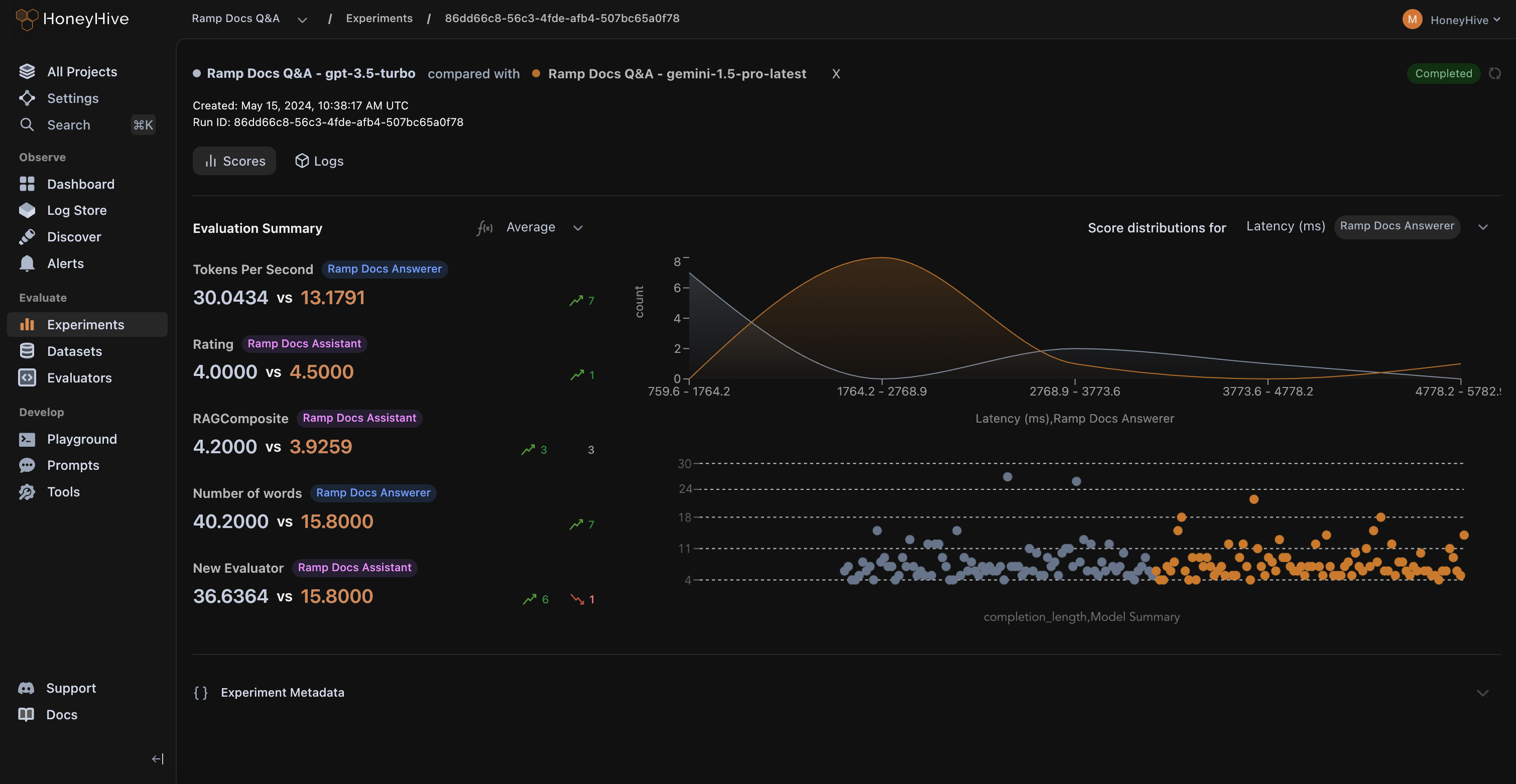
Validate agents pre-deployment on large test suites, compare versions, and catch regressions in CI/CD before users feel them.
.png)
.png)

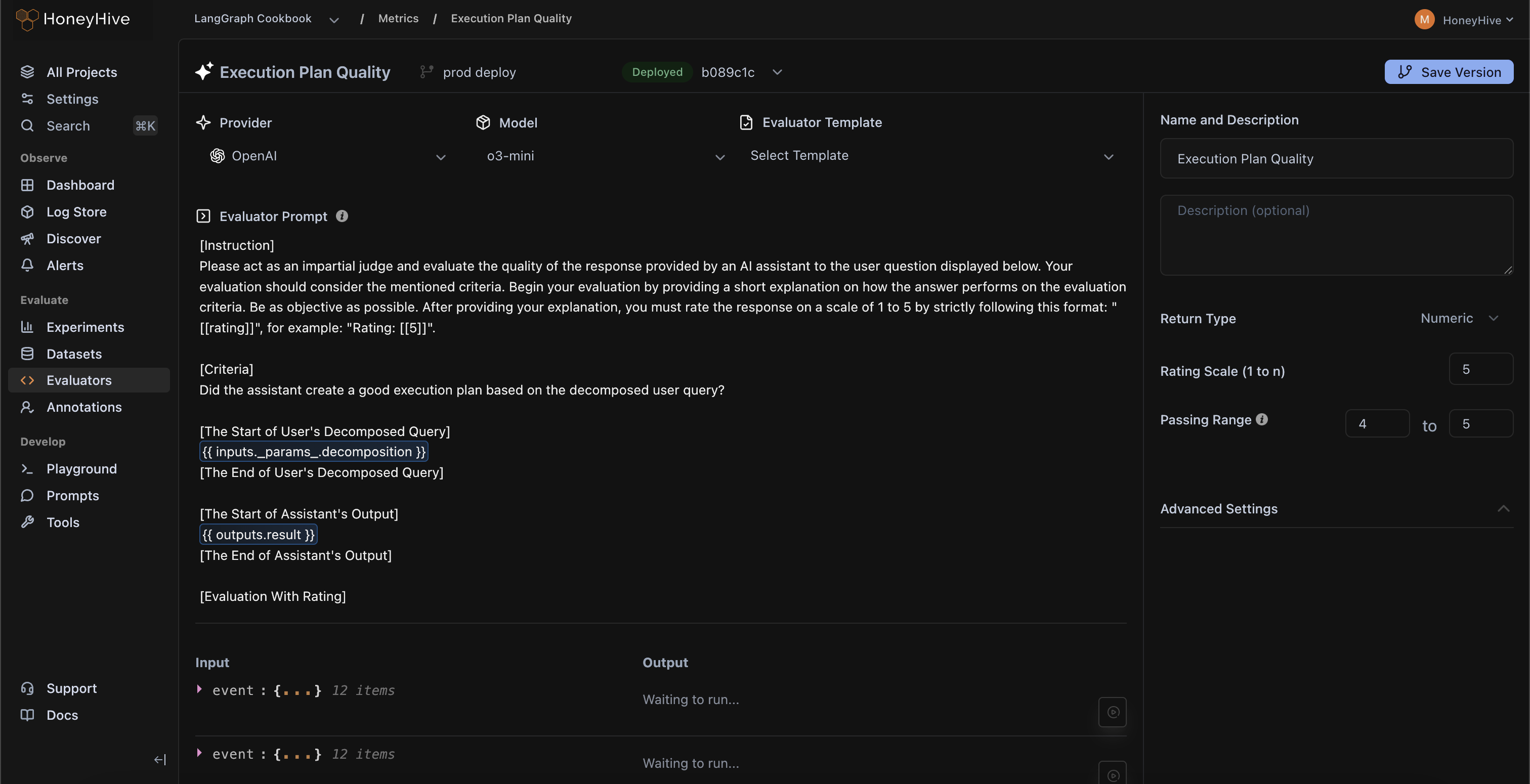
Give engineers and domain experts a single source of truth for prompts, datasets, and evaluators—synced between UI and code.

.png)

.png)
.png)
.png)
HoneyHive is built to handle sensitive PHI, PCI, and PII data at enterprise-scale.
Trust Center ↗


SOC-2 Type II, GDPR, and HIPAA compliant to meet your security needs.


Choose between multi-tenant SaaS, dedicated cloud, or self-hosting up to fully air-gapped.

RBAC with fine-grained permissions across multi-tenant workspaces.


Div Garg
Co-Founder

Rex Harris
Head of AI/ML
.png)
Cristian Pinto
CTO
.png)
.png)
